
我花掉那 600 美金的那一刻,其实心里是有一丝兴奋的:终于可以把所有零碎的自动化都串起来——消息进来、数据清洗、调用大模型、发回 Slack、同步到 Notion、再扔进数据库,最好还能自动重试、自动报警、自动生成周报。
网上都在说 n8n 是“工作流界的瑞士军刀”“AI 自动化的中枢”,我甚至在脑海里预演了未来的自己:喝着咖啡,看着工作流自己跑,像个指挥千军万马的将军。
现实是:我先当了三天运维,又当了两天接口调试员,然后当了一周“JSON 处理工”。流程跑通那一刻,我没有爽感,只有一种疲惫的清醒——它确实强,但它强得很“硬”,强得像一台机床:会用的人效率爆炸,不会用的人只会被切伤。
这篇文章不是黑 n8n,而是我花 600 美金买来的“祛魅笔记”:它到底适合谁?坑在哪里?以及——你要怎么用,才不至于被它反噬。
01 你以为你买的是自动化,实际你买的是“复杂性”
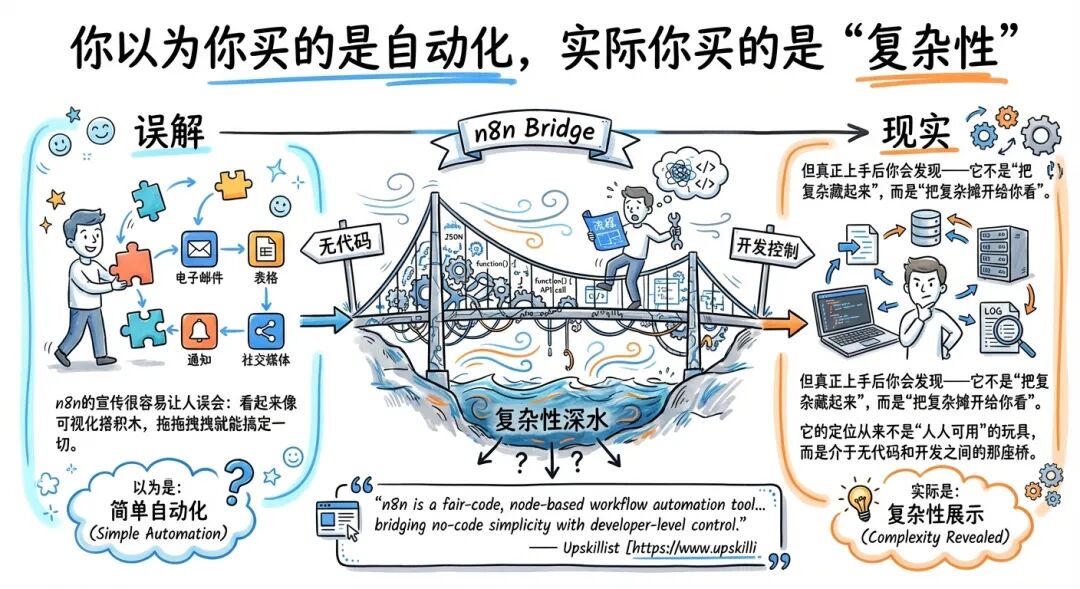
n8n 的宣传很容易让人误会:看起来像可视化搭积木,拖拖拽拽就能搞定一切。但真正上手后你会发现——它不是“把复杂藏起来”,而是“把复杂摊开给你看”。
它的定位从来不是“人人可用”的玩具,而是介于无代码和开发之间的那座桥。桥的另一端确实自由,但桥上风大,脚下是深水。
“n8n is a fair-code, node-based workflow automation tool… bridging no-code simplicity with developer-level control.” — Upskillist https://www.upskillist.com/blog/n8n-review/
祛魅的第一刀,是你会突然意识到:工作流自动化并不会自动变简单,它只是把“写代码的复杂性”换成“理解数据流的复杂性”。
尤其当你要做的不是“收到邮件→转发消息”这种小事,而是:
多分支(IF/ELSE)
循环(批量分页、迭代处理)
并行/合流
异常捕获与重试策略
多系统权限与凭证管理
大模型调用与上下文拼装(RAG、Embeddings)
n8n 的节点画布会让这一切变得“看得见”,但并不会让它“更轻”。你每多拖一个节点,本质上就是把系统复杂性多推进一步。
更扎心的是:你很难靠“蛮力拖节点”赢。你必须理解 JSON、理解 API、理解鉴权、理解错误码、理解幂等、理解延迟和超时。否则工作流不是跑不通,而是——跑通了也不稳定。
这也是很多人花钱之后崩溃的原因:你以为买的是省时间,结果买的是一套需要你补课的工程体系。
02 600 美金到底花哪了?真正烧钱的是“试错成本”
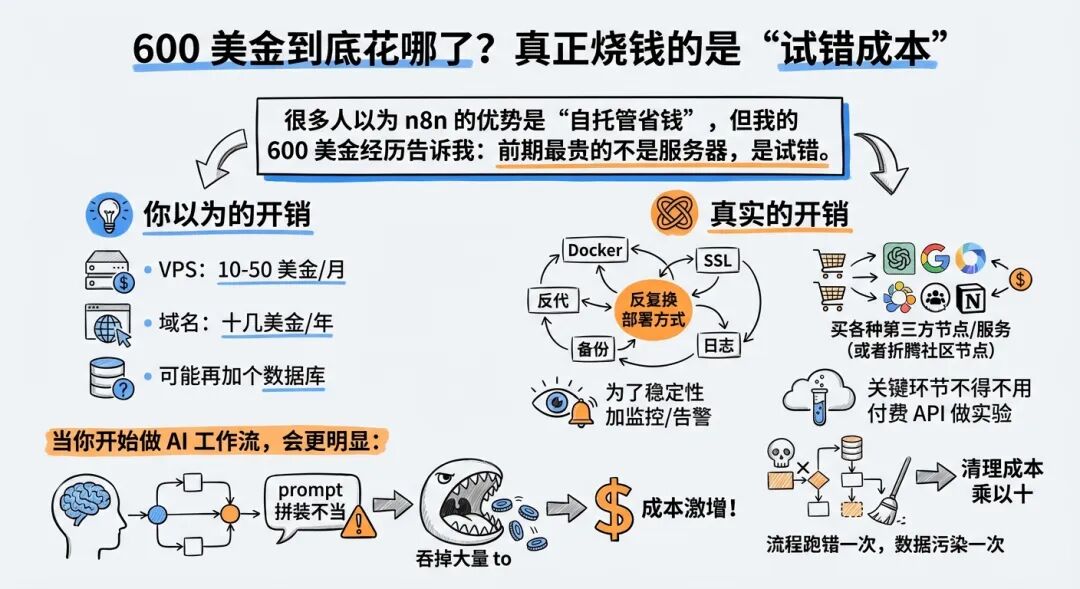
很多人以为 n8n 的优势是“自托管省钱”,但我的 600 美金经历告诉我:前期最贵的不是服务器,是试错。
你以为的开销:
VPS:10-50 美金/月
域名:十几美金/年
可能再加个数据库
真实的开销:
反复换部署方式(Docker、反代、SSL、备份、日志)
买各种第三方节点/服务(或者折腾社区节点)
为了稳定性加监控/告警
关键环节不得不用付费 API 做实验
流程跑错一次,数据污染一次,清理成本乘以十
当你开始做 AI 工作流,会更明显:一次 prompt 拼装不当,就会吞掉大量 token;一次循环没控住,就会触发上游限流;一次错误处理没写好,就会出现“半成功”状态,最难追。
更现实的是,n8n 的确适合复杂逻辑,但这意味着你会更倾向于把复杂都塞进去,最终形成“巨型工作流”,调试就像在盘一团毛线。
所以那 600 美金,本质不是“买工具”,而是“为学习曲线和试错过程付费”。如果你预算紧、时间更紧,n8n 很可能会让你产生一种错觉:怎么我越自动化越忙?
03 n8n 最迷人的地方:它不是工具,而是“编排层”
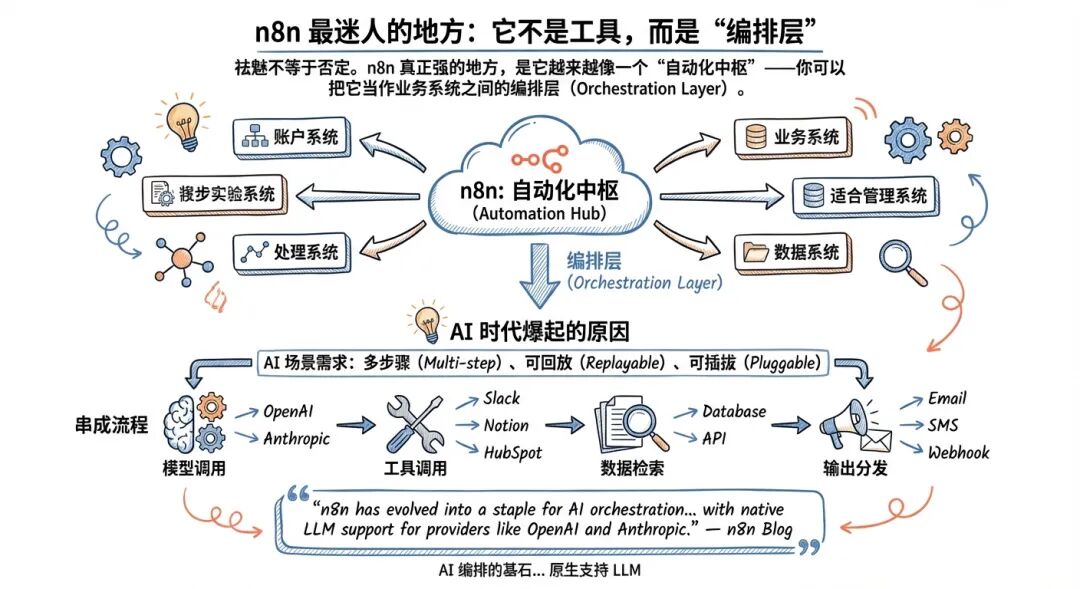
祛魅不等于否定。n8n 真正强的地方,是它越来越像一个“自动化中枢”——你可以把它当作业务系统之间的编排层(Orchestration Layer)。
这也是它能在 AI 时代爆起来的原因:AI 场景天然需要“多步骤、可回放、可插拔”的链路,把模型调用、工具调用、数据检索、输出分发串成流程。
“n8n has evolved into a staple for AI orchestration… with native LLM support for providers like OpenAI and Anthropic.” — n8n Blog https://blog.n8n.io/best-ai-workflow-automation-tools/
它的魅力在于:
1)逻辑没有天花板:分支、循环、并行、重试、子流程,你几乎可以把一个小型后台系统的业务逻辑搬上画布。
2)API 友好:任何能 API 访问的服务,都能被接进来;你不必等平台给“官方集成”。
3)AI 链路更顺:从触发→检索→调用模型→结构化输出→写入系统→通知,都能跑在一个统一的执行轨迹里。
4)自托管的可控感:成本可预测、数据可控、权限可控(前提是你真能把安全做好)。
甚至从市场趋势看,它的增长并不意外:自动化需求在上升,远程协作、AI 上线、系统碎片化,都在推着团队寻找“编排层”。
“n8n has surpassed 230,000 active global users as of late 2025.” — FlowLyn https://flowlyn.com/blog/n8n-user-count-statistics-growth
也就是说:n8n 的价值不在“省事”,而在“把复杂事变得可控”。你要的是一个能承载复杂度的容器,而不是一个替你思考的魔法棒。
04 真正让我祛魅的,是 2026 年那波安全漏洞:自托管不是“免死金牌”
很多人谈 n8n,自托管会被描述成一种“更安全、更自由”的选择:数据在自己手里,凭证自己管,想怎么改怎么改。
但 2026 年初曝出的那波高危漏洞,把我从“自托管浪漫主义”里直接拽出来:你掌控了服务器,也就继承了服务器的一切风险。
更可怕的是:这类漏洞的破坏半径很适配 n8n 的使用方式——n8n 恰恰会存放大量敏感信息:API keys、Webhook、数据库凭证、内部系统 token、企业消息系统权限,甚至大模型的 key。
一旦被拿下,不是“工作流坏了”,而是“整个自动化中枢被接管”。
“Six n8n CVEs disclosed in one day… a clear signal of systemic security weaknesses.” — Upwind Security https://www.upwind.io/feed/six-n8n-cves-one-day-workflow-security
Pillar Security 对“沙箱逃逸”等问题的分析,也强调了这类工作流系统的“高权限”属性:它天生处在企业数据与外部世界的交界处,攻击者一旦进来,价值极高。
“Sandbox escape critical vulnerabilities in n8n… exposes… enterprise AI systems to complete takeover.” — Pillar Security [https://www.pillar.security/blog/n8n-sandbox-escape-critical-vulnerabilities-in-n8n-exposes-hundreds-of-thousands-of-enterprise-ai-systems-to-complete-takeover]
这件事对我的影响是:从那天起,我不再把 n8n 当“自动化工具”,而把它当“生产系统”。
生产系统意味着什么?意味着你要做:
最小权限(谁能编辑工作流?谁能看凭证?)
凭证隔离与轮换
版本升级策略与回滚
网络隔离、反代、WAF、IP 白名单
审计日志、异常告警
重要工作流的测试与回放
这些事情不做,省下来的不是成本,而是未来要付的“更大的账”。
05 你不需要更多节点,你需要“工程化使用 n8n”的方法
当我对 n8n 祛魅之后,反而更能用好它:因为我不再追求“堆功能”,而是追求“可维护、可追踪、可扩展”。
这里给一套我后来总结的、适合个人/小团队的工程化用法(不玄学,纯落地):
1)把“巨型工作流”拆成模块:子流程/子工作流
不要把所有逻辑塞到一张画布上。把它拆成三层:
触发层(Webhook/定时/消息队列)
处理层(清洗、规则、AI 调用)
输出层(写库、发消息、归档)
每层独立成子流程,减少耦合。这样你调试时不会像在翻一整本电话簿。
2)先做“可观测性”,再谈自动化
你要能回答三个问题:
失败率多少?
失败发生在哪个节点?
失败的数据长什么样?
把日志、告警、重试策略先搭起来。没有这些,你的自动化只是“看起来在跑”。
3)把数据结构当合同:统一输入输出 JSON
n8n 最大的痛点其实是“数据在节点之间变形”。你要做的是: - 每个子流程明确输入字段、输出字段 - 关键字段命名统一 - 用固定结构承载错误信息(error_code、error_message、raw_response)
这会让你后续加节点、换节点不至于全盘重写。
4)AI 节点要“控成本、控风险”
如果你在 n8n 里接大模型,建议从一开始就做:
token 预算(长文本先摘要再推理)
prompt 模板化(版本管理)
输出结构化(JSON schema / 强约束)
失败兜底(模型超时、限流时走降级策略)
n8n 的 AI 很强,但 AI 的不确定性也会放大工作流的不稳定性。你必须把“随机性”关进笼子里。
06 哪些人该用 n8n?哪些人现在就该停手
祛魅之后最重要的事,是判断:你到底该不该继续投入。
适合 n8n 的人(建议继续)
你已经被 Zapier/Make 的“逻辑上限”卡过 - 你需要多系统、多步骤、强分支、强容错 - 你愿意学习 API / JSON / 基础运维 - 你把自动化当成“长期资产”,愿意工程化维护 - 你在做 AI 编排:RAG、Agent、多工具链路
一些服务公司之所以能把 n8n 做得很成功,本质上就是把它当“项目交付”,而不是“拖拉拽玩具”。
不适合 n8n 的人(建议止损)
你只想做极简自动化(两三步) - 你希望“无脑拖拽立刻出结果” - 你没有精力维护部署、升级、安全 - 你不能接受“调试是日常”的现实 - 你的业务强依赖稳定性,但团队没有工程能力
很多评论区会说“n8n 很直观”,也会有人说“n8n 让人挫败”。两边都没错:直观的是画布,挫败的是复杂系统本身。
07 结尾:这 600 美金没白花,它买走了我的幻想
我现在仍然在用 n8n,但用法完全变了:
我不再幻想“一套工作流解放全部人生”,而是把它当作一套需要设计、需要监控、需要迭代的自动化基础设施。
那 600 美金最终买走的,是我对“自动化工具”的幼稚想象——认为只要换个工具,一切就会变顺。事实是:工具不会替你消灭复杂度,它只会让复杂度以另一种形式出现。
如果你正准备入坑 n8n,我更想送你一句实话:
n8n 的门槛不在安装,而在你是否愿意把它当工程来做。
愿意,它就是生产力放大器;不愿意,它就是时间黑洞。
你也踩过 n8n 的坑吗?或者你花过多少钱才“醒悟”?
欢迎在评论区告诉我:你最痛的一次工作流翻车是什么——我也想看看,大家的 600 美金都交给了哪些“学费”。
来源列表(引用)
https://www.upskillist.com/blog/n8n-review/ - https://www.siit.io/tools/trending/n8n-review - https://blog.n8n.io/best-ai-workflow-automation-tools/ - https://flowlyn.com/blog/n8n-user-count-statistics-growth - https://thehackernews.com/2026/01/two-high-severity-n8n-flaws-allow.html - https://www.upwind.io/feed/six-n8n-cves-one-day-workflow-security